Imagine you have to create a CAD-grade application, e.g. drawing the entire wireframe of a space shuttle or showing the intricacies of 9-layer printed circuit board. Basically something that involves a heavy work to display the result on the screen. On top of that, the application is still expected to perform smoothly in case the user wants to pan/scroll around and zoom in/out.
The usual known trick to achieve this is by employing a backing store, i.e. off-screen buffer that serves as the target for the drawing operations. The user interface then takes the backing store and displays it to the user. Now panning is a matter of translation and zooming is just scaling. The backing store can be updated asynchronously, thus making the user interaction decoupled from the complexity of the rendering.
Moving to a higher ninja level, the backing store can be tiled. Instead of just one giant snapshot of the rendering output, it is broken down to small tiles, say 128x128 pixels. The nice thing is because each tile can be mapped as a texture in the GPU, e.g. via glTexImage2D. Drawing each textured tile is also a (tasty) piece of cake, GL_QUAD with glBindTexture.
Another common use-case for tiling is for online maps. You probably use it every day without realizing it in Google Maps, OpenStreetMap, or other similar services. In this case, the reason is to use tiles is mainly to ease the network aspect. Instead of sending a huge image representing the area seen by the user in the viewport, actually lots of small images are transported and stitched together by the client code in the web browser.
Here is an illustration of the concept. The border of each tile is emphasized. The faded area is what you don't see (outside the viewport). Of course every time you pan and zoom, new fresh tiles are fetched so as to cover the viewport as much as possible.
When I started to use the first generation iPhone years ago, I realized that the browser (or rather, its WebKit implementation) uses the very similar trick. Instead of drawing the web page straight to the screen, it uses a tiled backing store. Zooming (via pinching) becomes really cheap, it's a matter of scaling up and down. Flicking is the same case, translating textures does not bother any mobile GPU that much.
Every iOS users know that if you manage to beat the browser and flick fast enough, it tries to catch up and fills the screen as fast as possible but every now and then you'll see some sort of checkerboard pattern. That is actually the placeholder for tiles which are not ready yet.
Since all the geeks out there likely better understand the technique with a piece of code, I'll not waste more paragraphs and present you this week's X2 example: full-featured implementation of tiled backing store in < 500 lines of Qt and C++. You can get the code from the usual X2 git repository, look under graphics/backingstore. When you compile and launch it, use mouse dragging to pan around and mouse wheel to zoom in/out. For the impatient, see the following 50-second screencast (or watch directly on YouTube):
For this particular trick, what you render actually does not matter much (it could be anything). To simplify the code, I do not use WebKit and instead just focus on SVG rendering, in particular of that famous Tiger head. The code should be pretty self-explanatory, especially for the TextureBuffer class, but here is some random note for your pleasure.
At the beginning, every tile is invalid (=0). Every time the program needs to draw a tile, it checks first if the tile is valid or not. If yes, it substitutes it with the checkerboard pattern instead (also called the default texture) and triggers an asynchronous update process. During the update, the program looks for the most important tile which needs to be updated (usually the one closes to the viewport center). What is a tile update? It's the actual rendering of the SVG, clipped exactly to the rectangular bounding box represented by the tile, into a texture.
To show the mix-n-match, I actually use Qt built-in software rasterizer to draw the SVG. That demonstrates that, even though each tile is essentially an OpenGL texture, you are not forced to use OpenGL to prepare the tile itself. This is essentially mixing rasterization done by the CPU with the texture management handled by the GPU.
As I mentioned before, panning is a matter of adjusting the translation offset. Zooming is tricky, it involves scaling up (or down) the textures appropriately. At the same time, it also triggers an asynchronous refresh. The refresh function is nothing but to reset all the tiles to invalid again, which in turns would update each one by one. This gives the following effect (illustrated in the screenshot below). If suddenly you zoom in, you would see pixelated rendering (left). After a certain refresh delay, the tile update makes the rendering crisp again (right).
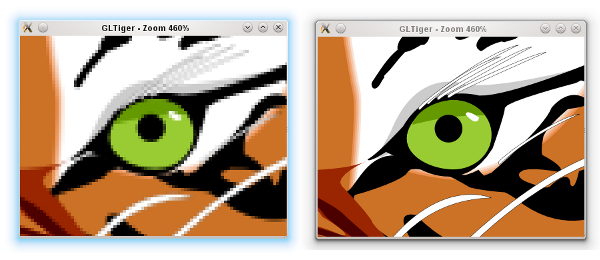
Because we still need to have the outdated tiles scaled up/down (those pixelated ones), we have to keep them around for a while until the refresh process is completed. This is why there is another texture buffer called the secondary background buffer. Rest assured, when none of the tiles in the background buffer is needed anymore, the buffer is flushed.
If you really want to follow the update and refresh, try to uncomment the debug compiler define. Beside showing the individual tiles better, that flag would also intentionally slows down both update and refresh so your eyes can have more time to trace them.
BTW how would you determine the tile dimension in pixels? Unfortunately this can vary from one hardware to another. Ideally it's not too small because you'd enjoy the penalty of logical overdraw. If it's too large, you might not be progressive enough. Trial and error, that can be your enlightenment process.
Being an example, this program has a lot of simplifications. First of all, usually you want the tile update to take place in a separate thread, and probably updating few tiles at once. With a proper thread affinity, this helps improving the overall perceptive smoothness. Also, in case you know upfront that it does not impact the performance that much, using texture filtering (instead of just GL_NEAREST) for the scaling would give a better zooming illusion.
You might also see that I decided not to use the tile cache approach in the texture buffer. This is again done for simplicity. The continuous pruning of unused textures ensures that we actually don't grow the textures and kill the GPU. If you really insist on the absolutely minimal amount of overdraw and texture usage, then go for a slightly complicated cache system.
Since I'm lazy, the example is using Open GL and quad drawing. If you want to run it on a mobile platform, you have patch it so that it works with Open GL ES. In all cases, converting it to use vertex and texture arrays is likely a wise initial step. While you are there, hook the touch events so you can also do the pinch-to-zoom effect.
If you are brave enough, here is another nice final finish (as suggested by Nicolas of InfoVis and PhiloGL fame). When you zoom in, the tiles in the center are prioritized. However, when you zoom out, the tiles nearby the viewport border should get the first priority, in order to fill the viewport as fast as possible.
Progressive rendering via a tiled backing store is the easiest way to take advantage of graphics processor. It's of course just one form, probably the simplest one, of hardware acceleration.



{kind=link}